
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
This article is based on a paper that to be presented at the CoopIS 2024 conference: Tiukhova, E., Salcuni, A., Oguz, C., Forte, F., Baesens, B., Snoeck, M. (2024). IML4DQ: Interactive Machine Learning for Data Quality with applications in Credit Risk. To be published in: Cooperative Information Systems. CoopIS 2024. Lecture Notes in Computer Science, Springer.
Human in the loop machine learning
The vast amounts of data collected by various information systems have driven the development of machine learning (ML), which can identify patterns in data and use the learned information to solve various tasks, such as predicting future outcomes. Many everyday tasks can be optimized by ML solutions, often requiring direct human interaction with these systems, being the focus of Human-Computer Interaction (HCI), which aims to design technologies that are both user-friendly and effective for people. When ML and HCI converge, we encounter Human-in-the-Loop Machine Learning (HITL-ML), which integrates human input into the ML lifecycle. There are several approaches to HITL-ML that differ in how control is shared between humans and machines [1]. In active learning, the machine is primarily in control, with minimal human input, such as labeling data. In Interactive ML (IML), there is more interaction between humans and machines, with humans providing incremental information to improve the ML model. Finally, in machine teaching, human expertise often takes precedence over the data-driven knowledge extracted by the machine [1].
Since IML balances control between humans and machines, it is often the preferred approach for incorporating human expertise into ML solutions in various domains. This is typically achieved by integrating a user interface (UI) into the ML system, allowing users to provide input to the model while also interacting with its output. This creates four key components within an IML system: the user, the data, the model, and the user interface (Fig. 1).
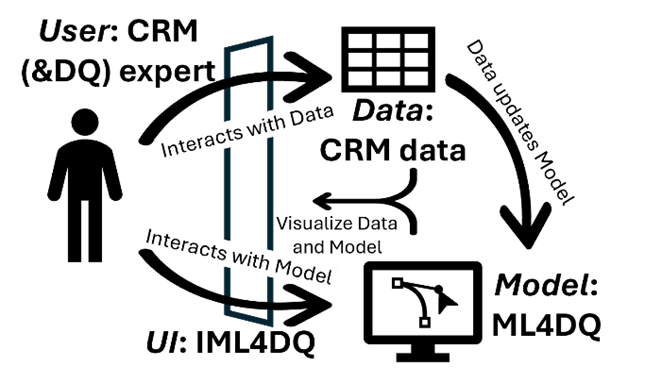
Figure 1. IML system components. Adapted from [2]
What domains can benefit from IML solutions? The answer lies in the user component: where human expertise is essential, integrating it into the ML pipeline can significantly increase the effectiveness of the system. In this article, we will focus on data quality — an area where both ML and human expertise play a critical role. So, why not combine them for optimal results?
Why is data quality important? Why in credit risk management?
The increasing reliance on data in analytical solutions raises the bar for data quality. This is especially critical in areas where incorrect data-driven decisions can lead to significant reputational or financial losses, such as credit risk management (CRM). The goal of credit risk management is to accurately assess a borrower’s risk in order to avoid potential losses [3]. Poor quality data used in this assessment can result in financial institutions not only losing money from bad loans, but also damaging their reputation by denying credit to legitimate customers. In addition, regulatory requirements mandate that financial institutions implement proper data checks to remain compliant. But how do you ensure quality data, especially at the high volumes typical of large financial organizations? Manual verification becomes impractical at this scale, but ML can provide a solution by learning from the data itself. What if a non-ML expert, whose insights are critical to the process, needs to assess DQ? This is where IML comes in as a valuable tool.
Interactive ML for DQ assessment in Credit Risk Management
In order to investigate the extent to which the intersection of IML and DQ domains actually adds value in the CRM domain, we have developed a prototype of a user interface built on top of the ML framework built to detect DQ issues in CRM data [4] (ML4DQ framework), with the combined solution abbreviated as IML4DQ. Figure 1 shows how we specify the IML components in IML4DQ. The ML4DQ framework combines the iForest [5] and Autoencoder [6] models, which are commonly used in anomaly detection [7], since DQ issues are anomalies — unexpected deviations in the data. CRM data is preprocessed to reflect monthly changes, with anomalies appearing as unusual shifts in loan data. The system includes explainable AI provided by local SHAP values [8,9] for each detected DQ issue to facilitate expert feedback on the model outputs. The results of the expert feedback outlined in the related research showed that this approach helps to detect real DQ issues [4].
So far, so good! Now, to ensure that the ML4DQ framework can be used by a user regardless of ML or programming knowledge, we add a UI on top of the model. Figure 2 shows the UI of the developed system.
How does this enhanced system enable human involvement? The IML literature defines several tasks where a human interacts with an ML system [2]. The task of Feedback Assignment involves input interfaces: we enable this task by allowing a human to choose which data to feed into the model (window B), or which features to use by the model (window C), as well as which model type (window D). The Sample Review task allows the user to review the model output: we make this possible in the Excel output file (see window A), where the top DQ issues are stored along with their local explanations. The Task Overview interface provides information about the task status (as implemented in window F). Finally, the Model Inspection task provides an overview of the model quality. We proxy this task by generating local SHAP explanations in the output file that allow a user to understand the model’s reasoning for marking a loan as having a DQ issue.
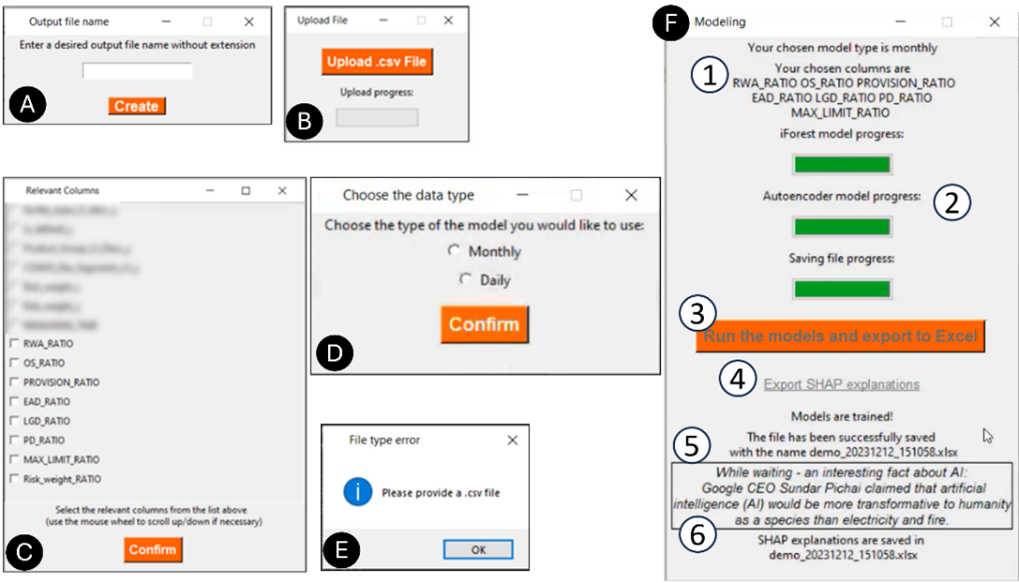
Figure 2. UI of IML4DQ
In addition to its focus on IML tasks, IML4DQ has also been designed according to the best principles of functional UI design [10]. In order to provide informative feedback to the user, i.e. to inform the user about the progress in the tool, the UI includes progress bars, notifications about the completion of a task, as well as reminders about the choices made in previous steps. The UI is consistent in design, color, and layout of widgets. The dialog with the user is simple and natural: each step has its own screen with the information relevant to that step; at the same time, to minimize the user’s memory load, the final screen provides an overview of the choices made in the previous steps. To avoid misuse of the tool, we try to prevent errors in the tool itself: its documentation explains the data preparation and the functionality of the application; the widgets and screens are given informative titles, and negative paths are handled with clear error messages.
How is IML4DQ perceived?
We conducted the interviews with potential stakeholders from a large international bank. We investigated their attitude towards DQ in general as well as attitude towards our IML4DQ solution and intention to use it in their work-related activities. Stakeholders positively perceive the need for high DQ in CRM, acknowledging both the difficulty of manual DQ assessment and the benefits of automating DQ processes. The motivation to detect DQ issues comes from different social sources, with government and management regulations being the strongest motivators. Regarding the IML4DQ solution, the tool is perceived as useful and easy to use, with the design principles of consistency and error prevention being the most fulfilled. Most of the respondents intend to use the application if it is developed in production.
What is next?
While interviewing potential stakeholders, we collected useful feedback and suggestions for improvement of both the ML4DQ framework and its IML4DQ extension. The ML4DQ framework is recommended to be extended to include impact estimation of DQ issues, support for categorical features and extension to a semi-supervised setting. The IML4DQ tool is expected to be improved by simplifying the model output and making the UI more modern, while also moving the details on data preparation and SHAP explanations from the documentation to the application itself. All the improvements are to be re-evaluated in the future research iterations.
References
- [1] Mosqueira-Rey, E., Hernández-Pereira, E., Alonso-Ríos, D., Bobes-Bascarán, J., Fernández-Leal, A.: Human-in-the-loop machine learning: a state of the art. Artif. Intell. Rev. 56(4), 3005–3054 (aug 2022)
- [2] Dudley, J.J., Kristensson, P.O.: A review of user interface design for interactive machine learning. ACM Trans. Interact. Intell. Syst. 8(2) (jun 2018)
- [3] Baesens, B., Roesch, D., Scheule, H.: Credit risk analytics: Measurement techniques, applications, and examples in SAS. John Wiley & Sons (2016)
- [4] Tiukhova, E., Salcuni, A., Oguz, C., Niglio, M., Storti, G., Forte, F., Baesens, B., Snoeck, M.: Boosting credit risk data quality using machine learning and eXplainable AI Techniques. In: Machine Learning and Principles and Practice of Knowledge Discovery in Databases: International Workshops of ECML PKDD 2023, Turin, Italy, September 18–22, 2023, Revised Selected Papers, Part V. Springer Cham (2024)
- [5] Liu, F.T., Ting, K.M., Zhou, Z.H.: Isolation forest. In: 2008 Eighth IEEE International Conference on Data Mining. pp. 413–422 (2008)
- [6] Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. science 313(5786), 504–507 (2006)
- [7] Tiukhova, E., Reusens, M., Baesens, B., Snoeck, M.: Benchmarking conventional outlier detection methods. In: Research Challenges in Information Science: 16th International Conference, RCIS 2022, Barcelona, Spain, May 17–20, 2022, Proceedings. pp. 597–613. Springer (2022)
- [8] Lundberg, S.M., Erion, G., Chen, H., DeGrave, A., Prutkin, J.M., Nair, B., Katz, R., Himmelfarb, J., Bansal, N., Lee, S.I.: From local explanations to global understanding with explainable ai for trees. Nat. Mach. Intell. 2(1), 2522–5839 (2020)
- [9] Antwarg, L., Miller, R.M., Shapira, B., Rokach, L.: Explaining anomalies detected by autoencoders using Shapley Additive Explanations. Expert Syst. Appl. 186, 115736 (2021)
- [10] Ruiz, J., Serral, E., Snoeck, M.: Unifying functional user interface design principles. Int. J. Hum. Comput. Interact. 37(1), 47–67 (2021)