
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by Philipp Borchert.
Key Takeaways
- Training multilingual LLMs continues to present significant challenges, despite notable advancements in recent models.
- The scarcity of pretraining resources is a major constraint, particularly affecting under-resourced languages.
- Merely scaling up the parameters and size of training corpora is inadequate for achieving performance in other languages that matches English.
- Cross-lingual transfer and adaptive strategies are promising approaches for enhancing LLM capabilities across multiple languages.
Introduction
Large Language Models (LLMs) are primarily trained using English data. For example, models such as Llama 3 have been reported to use datasets that consist of up to 95% English content (Meta 2024). Although these models have shown consistent improvements in performance across various languages over the years, these enhancements have not scaled proportionally with the increases in pretraining data volumes. While enlarging the pretraining corpus can enhance language modeling capabilities, it does not necessarily translate into improved performance on downstream tasks (Shliazhko et al., 2023; Scao et al., 2023). This suggests that the development of multilingual LLMs involves more than merely expanding the model’s parameters and the size of pretraining corpora.
Challenges in training multilingual LLMs
Training multilingual Large Language Models presents several challenges. A primary issue is the scarcity of high-quality training data for languages other than English, which affects the models’ ability to learn and generalize effectively across different linguistic contexts. Additionally, effective and efficient tokenization of non-English languages and scripts other than Latin is crucial for multilingual performance. Tokenizers are extended to efficiently encode a diverse range of languages, which includes managing an expanded vocabulary. This increase in vocabulary size and the need to encode language-specific information lead to inter-language competition for model capacity (Blevins et al., 2024). The phenomenon, known as the “curse of multilinguality,” results in performance degradation, even in the model’s dominant language, typically English.
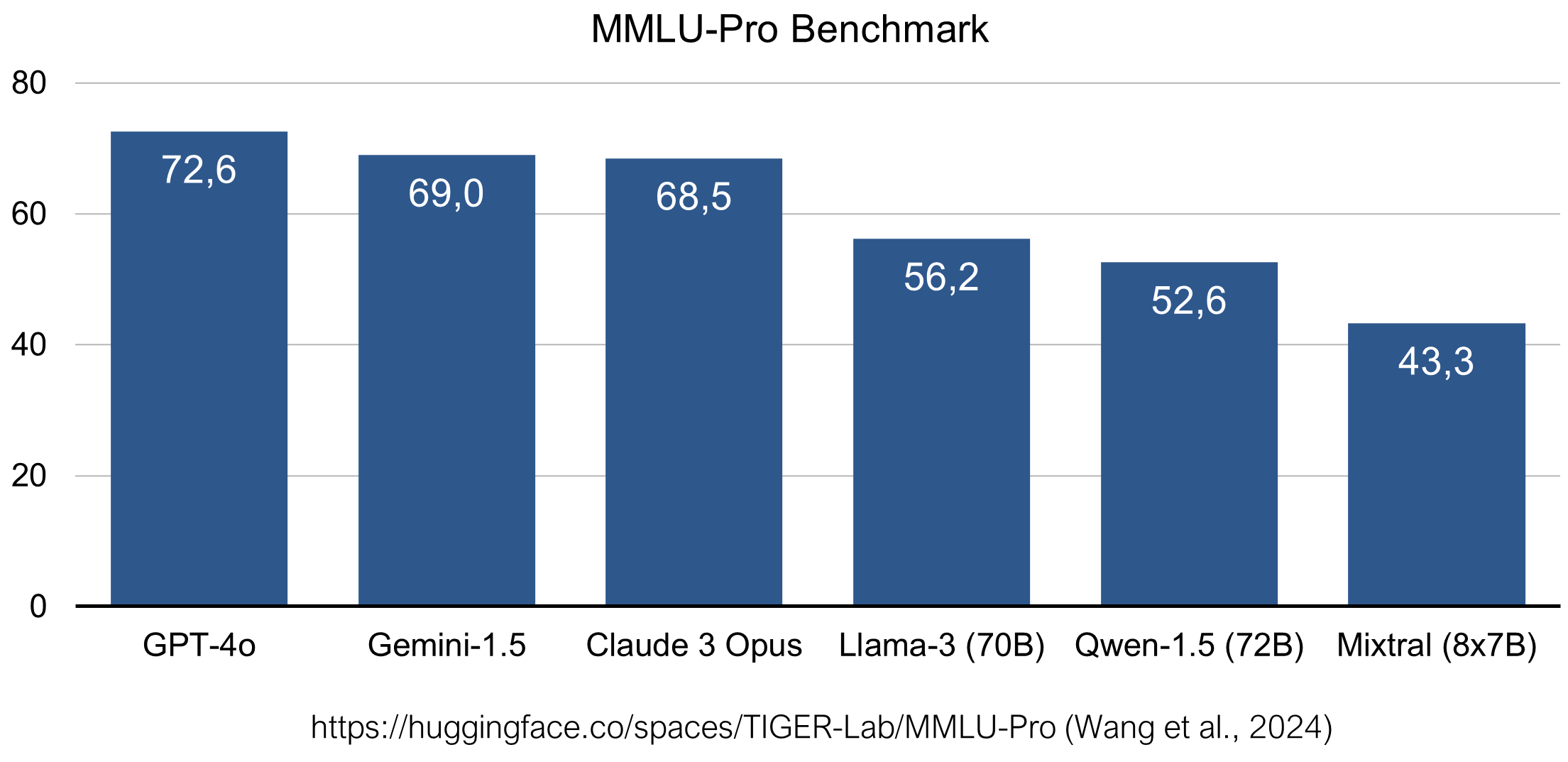
For instance, Bloom (Scao et al., 2023), with 176 billion parameters, was specifically designed to train on a more balanced language distribution within its pretraining corpora. Despite these efforts, its performance on benchmarks and in practical applications remains significantly lower compared to the smaller Llama and Mistral models.
Current approaches
To enhance multilingual performance, several strategies have been adopted. Models like Mistral (Jiang et al., 2023) and Aya (Üstün et al., 2024) focus on training with data distributions that more accurately reflect real-world usage, predominantly in English, but also including other commonly used languages such as German, French, and Spanish. These models have also improved their tokenization techniques to better match their pretraining data and intended deployment scenarios. However, these advancements do not necessarily benefit the thousands of under-resourced languages. Cross-lingual transfer approaches have been specifically developed to extend LLM capabilities to these lower-resource languages. Such strategies often leverage the strong performance of machine translation models like NLLB (NLLB Team, 2022). For example, machine translation systems can be integrated directly into LLMs, enabling seamless interaction across all languages supported by the translation model (Schmidt et al., 2024). Alternatively, adapting LLMs to each language with cross-lingual transfer for specific downstream tasks can provide state-of-the-art task performance (Borchert et al., 2024).
Conclusion
Training LLMs to proficiently handle a wide range of languages remains a significant challenge. Recent research indicates that simply scaling model capacity and collecting larger training corpora is insufficient. While recent LLM developments have concentrated on high-resource languages, cross-lingual transfer techniques offer a means to extend the benefits and capabilities of LLMs to lower-resource languages.
References:
- Üstün, A., Aryabumi, V., Yong, Z.-X., Ko, W.-Y., D’souza, D., Onilude, G., … Hooker, S. (2024). Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2402.07827
- Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., … Chen, W. (2024). MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2406.01574
- Shliazhko, O., Fenogenova, A., Tikhonova, M., Kozlova, A., Mikhailov, V., & Shavrina, T. (2024). mGPT: Few-Shot Learners Go Multilingual. Transactions of the Association for Computational Linguistics, 12, 58–79.
- Scao, T. L., Fan, A., Akiki, C., Pavlick, E., … Wolf, T. (2023). BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2211.05100
- Meta (2024). Introducing Meta Llama 3: The most capable openly available LLM to date. Retrieved from https://ai.meta.com/blog/meta-llama-3/
- Blevins, T., Limisiewicz, T., Gururangan, S., Li, M., Gonen, H., Smith, N. A., & Zettlemoyer, L. (2024). Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2401.10440
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., las Casas, D. de, … Sayed, W. E. (2023). Mistral 7B. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2310.06825
- Schmidt, F. D., Borchert, P., Vulić, I., & Glavaš, G. (2024). Self-Distillation for Model Stacking Unlocks Cross-Lingual NLU in 200+ Languages. arXiv [Cs.CL]. Retrieved from http://arxiv.org/abs/2406.12739
- Borchert, P., Vulić, I., Moens, M. F. & De Weerdt, J. (2024). Language Fusion for Parameter-Efficient Cross-lingual Transfer. Retrieved from https://openreview.net/forum?id=EKXcrktzuk