
Contributed by: Eugen Stripling, Seppe vanden Broucke and Bart Baesens
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Profit maximization is a main business requirement of corporate organizations, hence a data science application should focus on the profitability of a given business setting [1, 2]. The adaptation of analytics to a specific business application (e.g., churn) is crucial, since it leads to
better decision making. Insights from the analytical model support business decisions that allow attaining the maximum net profit, return, payoff, or value [3]. We refer to this value-centric approach as profit-driven business analytics.
In the spirit of the value-centric approach, we briefly outline in this column our new profit-driven modeling technique called ProfLogit [4]. Our associated research paper has been recently accepted for publication by the international journal of Swarm and Evolutionary Computation. A software implementation of ProfLogit is available at: https://github.com/ estripling/proflogit-python.
For a churn management campaign, a predictive model is typically built such that it identifies customers who are about to leave the company (i.e., churners) as accurately as possible. Such model does not take into consideration the costs and benefits that originate from the retention campaign. To guarantee the success of the campaign, scarce marketing resources should focus on churners that are the most valuable to the organization. Hence, correctly predicting a customer as a churner is not enough—it is also vital for the company to discriminate within the pool of churners in order to retain the valuable customers.
The expected maximum profit measure for customer churn (EMPC) is a first step toward this ambitious goal [2, 5]. It integrates the costs and benefits associated with the retention campaign into a coherent performance measure and allows users to select the most profitable churn prediction model. Yet, the EMPC solely permits a profit-based model selection, the internal decision mechanisms of the classification model are still optimized according to some non-profit objective function.
ProfLogit has been developed to close this gap by changing the objective function of the logistic model such that the regression coefficients are directly optimized for maximizing the EMPC measure in the model construction step [4, 6]. Given the complex nature of the optimization problem, ProfLogit makes use of a real-coded genetic algorithm, which finds an optimal solution by mimicking the biological process of evolution.
In a benchmark study with nine real-world churn data sets, we compared ProfLogit to other common linear classifiers. As a result, our ProfLogit technique attains the overall highest, out-of-sample EMPC performance (see Figure). The figure also reveals the profit-accuracy discrepancy, a pattern also observed by Verbraken et al. [5]. That is, ProfLogit achieves the highest profit, but, at the same time, performs weak in terms of accuracy-based measures. This highlights the importance of our proclaimed statement that the consideration of accuracy alone is not sufficient and more attention must be paid to profitability when building the predictive model. With ProfLogit, users can create a profit-oriented classification model for retention campaigns. We developed ProfLogit because we believe that the application of profit-driven business analytics is vital for corporate organizations to stay competitive.
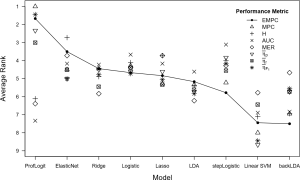 |
ProfLogit is the overall most profitable churn model.
References
- Wouter Verbeke, Karel Dejaeger, David Martens, Joon Hur, and Bart Baesens. New Insights into Churn Prediction in the Telecommunication Sector: a Profit Driven Data Mining Approach. European Journal of Operational Research, 218(1):211–229, 2012.
- Tomas Verbraken. Business-Oriented Data Analytics: Theory and Case Studies. PhD thesis, Department of Decision Sciences and Information Management, Faculty of Economics and Business, KU Leuven, Leuven, Belgium, 2013. Ph.D. Dissertation.
- Wouter Verbeke, Bart Baesens, and Cristián Bravo. Profit Driven Business Analytics: a Practitioner’s Guide to Transforming Big Data into Added Value. Wiley and SAS Business Series. John Wiley & Sons, 2017.
- Eugen Stripling, Seppe vanden Broucke, Katrien Antonio, Bart Baesens, and Monique Snoeck. Profit Maximizing Logistic Model for Customer Churn Prediction Using Genetic Algorithms. Swarm and Evolutionary Computation, 2017. doi: 10.1016/j.swevo.2017.10.010. In Press.
- Thomas Verbraken, Wouter Verbeke, and Bart Baesens. A Novel Profit Maximizing Metric for Measuring Classification Performance of Customer Churn Prediction Models. IEEE Transactions on Knowledge and Data Engineering, 25(5):961–973, 2013.
- Eugen Stripling, Seppe vanden Broucke, Katrien Antonio, Bart Baesens, and Monique Snoeck. Profit Maximizing Logistic Regression Modeling for Customer Churn Prediction. In 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pages 1–10, Paris, France, 2015. IEEE. doi: 10.1109/DSAA.2015.7344874.