
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
Contributed by Prof. dr. Seppe vanden Broucke and Prof. dr. Bart Baesens.
In April of this year, a team of researchers at MIT, the California Institute of Technology, the Northeastern University, and the NSF Institute for AI and Fundamental Interactions published a paper proposing an interesting alternative for the classic MLP architecture: Kolmogorov–Arnold Networks (KAN) [1]. The paper and the associated repository [2] rapidly spread around within the machine learning community, and in a couple of days, people were running their own experiments and working on accelerated implementations that could run on a GPU. In this article, we take a quick look at what makes KANs different, and where we are at a couple of months later.
What are KANs?
KANs are named as such because they are inspired by the Kolmogorov-Arnold representation theorem. This theorem, also called the superposition theorem, states that every multivariate continuous function can be represented as a superposition of the two-argument additions of continuous functions of one variable. What it basically proofs is that complex functions can be decomposed into simpler, one-dimensional functions:
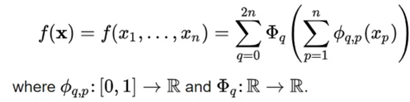
The question here is then obviously what 𝚽 should be. I.e. what is this simple one dimensional function? We can rely on the same building block as is used by generalized additive models (GAMs): a spline. Splines are mathematical functions that enable the construction of smooth curves by connecting a series of control points whilst ensuring continuity and smoothness. Popular ones are B-splines and Bezier curves.
By the way, if you were thinking about GAMs from the moment the Kolmogorov–Arnold representation theorem was mentioned: you are basically correct. GAMs utilize the same fundamental theorem but drop the outer sum of the formula above, demanding instead that the function belongs to a simpler class:
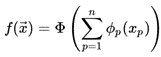
On top of this, the splines of a GAM model are fitted using a technique called backfitting, while KANs are fitted using the same SGD-based optimizers and autograd as used for other neural networks.
KANs differ from traditional MLPs in the sense that they replace the fixed activation functions of neurons with learnable B-splines. This allows KAN networks to model complex functions whilst retaining interpretability and with less parameters. Unlike MLPs, where neurons which serve as rather passive units for transmitting signals (and the weights to the heavy lifting), neurons in KANs are active participants in the learning process. The following figure illustrates the differences in more detail:
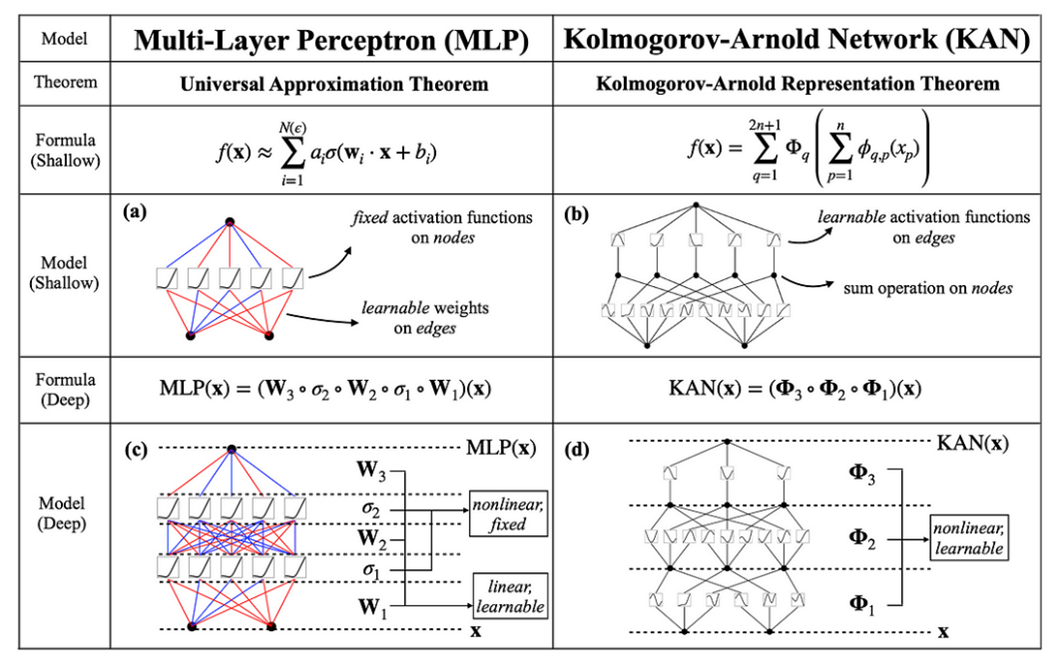
Source: [1].
Note that in a KAN, the edges represent the learned splines, rather than weights. The nodes represent a simple fixed sum operation, instead of a fixed activation function.
Advantages and Disadvantages
The elegant underlying theory of KANs leads to a couple of appealing advantages when compared to classical MLP networks. First, based on the fact that the network learns a set of splines, this offers a potential for simplicity where less neurons are needed to learn a task compared to an MLP network. Moreover, the use of splines leads to networks which can be easier to interpret than the more black-box nature of an MLP.
An additional benefit of the fact that the network actively learns activation functions is that KANs are more likely to suffer less from the issue of “catastrophic forgetting”, i.e. the tendency to produce completely erroneous predictions when extrapolating outside the boundaries of the training data. MLPs typically suffer a lot from this, whereas KANs do a better job here:
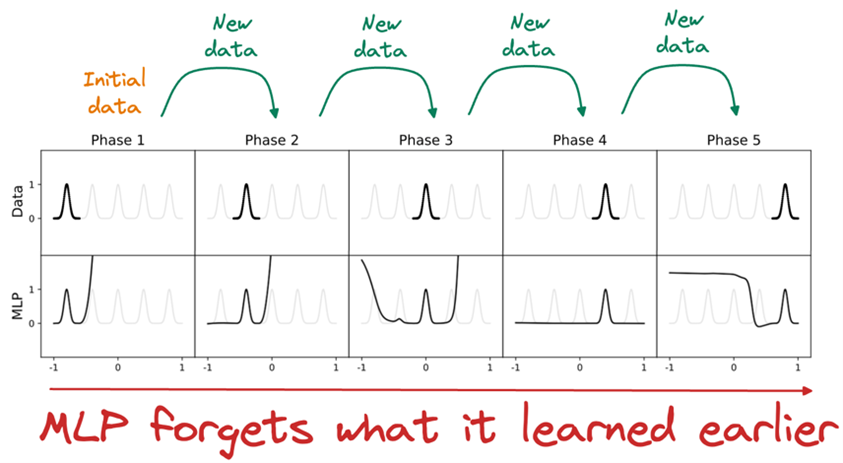
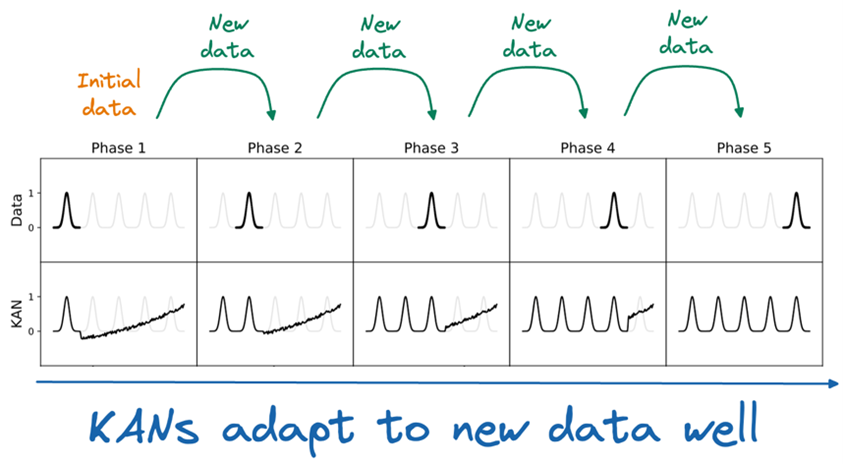
Source: [3].
In terms of disadvantages, they mainly stem from computational issues as well as reduced flexibility. Due to the nature of splines, KANs will typically be slower to train and to do inference with. The nature of the network architecture where nodes indicate sum operations might also make KANs less extendible or flexible as compared to traditional weight-focused networks.
Future Directions
Like mentioned at the start, ever since the paper on KANs was released, lots of other researchers and practitioners have been experimenting with them and extending the framework with new techniques and implementations. Some of the hallmark pieces of progress are listed below:
- We start getting a whole series of implementations, many of which focus on making the training more efficient, e.g. [4]
- People start using KANs for time series [5]
- KANs are being used for imagery using Convolutional KANs [6] and graphs [7]
- Relu-KAN shows that the network can be implemented using Matrix Addition, Dot Multiplication, and ReLU only, making the implementation 20 times more efficient [8]
- People start playing around with alternative basis functions other than B-splines, including Fourier decomposition, Chebyshev polynomials (similar as was done in ChebNet), Jacobi polynomials, Radial Basis Functions, and Wavelets. Check out [9] for a completely overview of what has been done in the space of a couple months
Are KANs here to stay? It certainly seems so. We haven’t reached GPT-4 levels of GenAI implementations yet, but some early results look promising, such as this attempt to replicate GPT-2 using KANs with 25% fewer parameters [10].
References
[1]: https://arxiv.org/abs/2404.19756
[2]: https://github.com/KindXiaoming/pykan
[3]: https://www.dailydoseofds.com/a-beginner-friendly-introduction-to-kolmogorov-arnold-networks-kan/#kan-vs-mlp
[4]: https://github.com/Blealtan/efficient-kan
[5] https://arxiv.org/abs/2405.08790
[6] https://github.com/AntonioTepsich/Convolutional-KANs
[7] https://arxiv.org/abs/2406.13597
[8] https://arxiv.org/abs/2406.02075
[9] https://github.com/mintisan/awesome-kan
[10] https://github.com/CG80499/KAN-GPT-2