
Contributed by: Seppe vanden Broucke, Bart Baesens
This article first appeared in Data Science Briefings, the DataMiningApps newsletter. Subscribe now for free if you want to be the first to receive our feature articles, or follow us @DataMiningApps. Do you also wish to contribute to Data Science Briefings? Shoot us an e-mail over at briefings@dataminingapps.com and let’s get in touch!
In this article, we take a quick look at how web scraping can be useful in the context of data science projects. Web “scraping” (also called “web harvesting”, “web data extraction” or even “web data mining”), can be defined as “the construction of an agent to download, parse, and organize data from the web in an automated manner”. Or, in other words: instead of a human end-user clicking away in their web browser and copy-pasting interesting parts into, say, a spreadsheet, web scraping offloads this task to a computer program which can execute it much faster, and more correctly, than a human can.
The automated gathering of data from the Internet is probably as old as the Internet itself, and the term “scraping” in itself has been around for much longer than the web, even. Before “web scraping” became popularized as a term, a practice known as “screen scraping” was already well-established as a way to extract data from a visual representation—which in the early days of computing (think 1960s-80s) often boiled down to simple, text-based “terminals”. Just as today, people around this time were already interested in “scraping” off large amounts of text from such terminals and store this data for later use.
When surfing around the web using a normal web browser, you’ve probably encountered multiple sites where you considered the possibility of gathering, storing, and analyzing the data present on the site’s pages. Especially for data scientists, whose “raw material” is data, the web exposes a lot of interesting opportunities. In such cases, the usage of web scraping might come in handy. If you can view some data in your web browser, you will be able to access and retrieve it through a program. If you can access it through a program, the data can be stored, cleaned, and used in any way.
No matter your field of interest, there’s almost always a use case to improve or enrich your practice based on data. “Data is the new oil”, so the common saying goes, and the web has a lot of it.
We’re working on a new book entitled “Web Scraping for Data Science with Python”, which’ll be geared towards data scientists who want to adopt web scraping techniques in their workflow. Stay tuned for more information in the coming issues of Data Science Briefings and over at dataminingapps.com. As a sneak preview, we’re sharing a summarized version of one of the use cases from the upcoming book.
Our goal is to construct a social graph of S&P 500 companies and their interconnectedness through their board members. We’ll start from the S&P 500 page at Reuters: https://www.reuters.com/finance/markets/index/.SPX to obtain a list of symbols:
from bs4 import BeautifulSoup
import requests
import re
session = requests.Session()
sp500 = 'https://www.reuters.com/finance/markets/index/.SPX'
page = 1
regex = re.compile(r'/finance/stocks/overview/.*')
symbols = []
while True:
print('Scraping page:', page)
params = params={'sortBy': '', 'sortDir' :'', 'pn': page}
html = session.get(sp500, params=params).text
soup = BeautifulSoup(html, "html.parser")
pagenav = soup.find(class_='pageNavigation')
if not pagenav:
break
companies = pagenav.find_next('table', class_='dataTable')
for link in companies.find_all('a', href=regex):
symbols.append(link.get('href').split('/')[-1])
page += 1
print(symbols)
Once we have obtained a list of symbols, another script will visit the board member pages for each of them (e.g. https://www.reuters.com/finance/stocks/company-officers/MMM.N), fetch out the table of board members, and store it as a pandas data frame:
from bs4 import BeautifulSoup
import requests
import pandas as pd
session = requests.Session()
officers = 'https://www.reuters.com/finance/stocks/company-officers/{symbol}'
symbols = ['MMM.N', [...], 'ZTS.N']
dfs = []
for symbol in symbols:
print('Scraping symbol:', symbol)
html = session.get(officers.format(symbol=symbol)).text
soup = BeautifulSoup(html, "html.parser")
officer_table = soup.find('table', {"class" : "dataTable"})
df = pd.read_html(str(officer_table), header=0)[0]
df.insert(0, 'symbol', symbol)
dfs.append(df)
df = pd.concat(dfs)
df.to_pickle('data.pkl')
This sort of information can lead to a lot of interesting use cases, especially in the realm of graph and social network analytics, take a look at our research page around this topic. We can use our collected information to export a graph and visualize it using Gephi, a popular graph viz tool:
import pandas as pd
import networkx as nx
from networkx.readwrite.gexf import write_gexf
df = pd.read_pickle('data.pkl')
G = nx.Graph()
for row in df.itertuples():
G.add_node(row.symbol, type='company')
G.add_node(row.Name,type='officer')
G.add_edge(row.symbol, row.Name)
write_gexf(G, 'graph.gexf')
The output file can be opened in Gephi, filtered, and modified. The following figure shows a snapshot of the egonets of order 3 for Apple, Google, and Amazon:
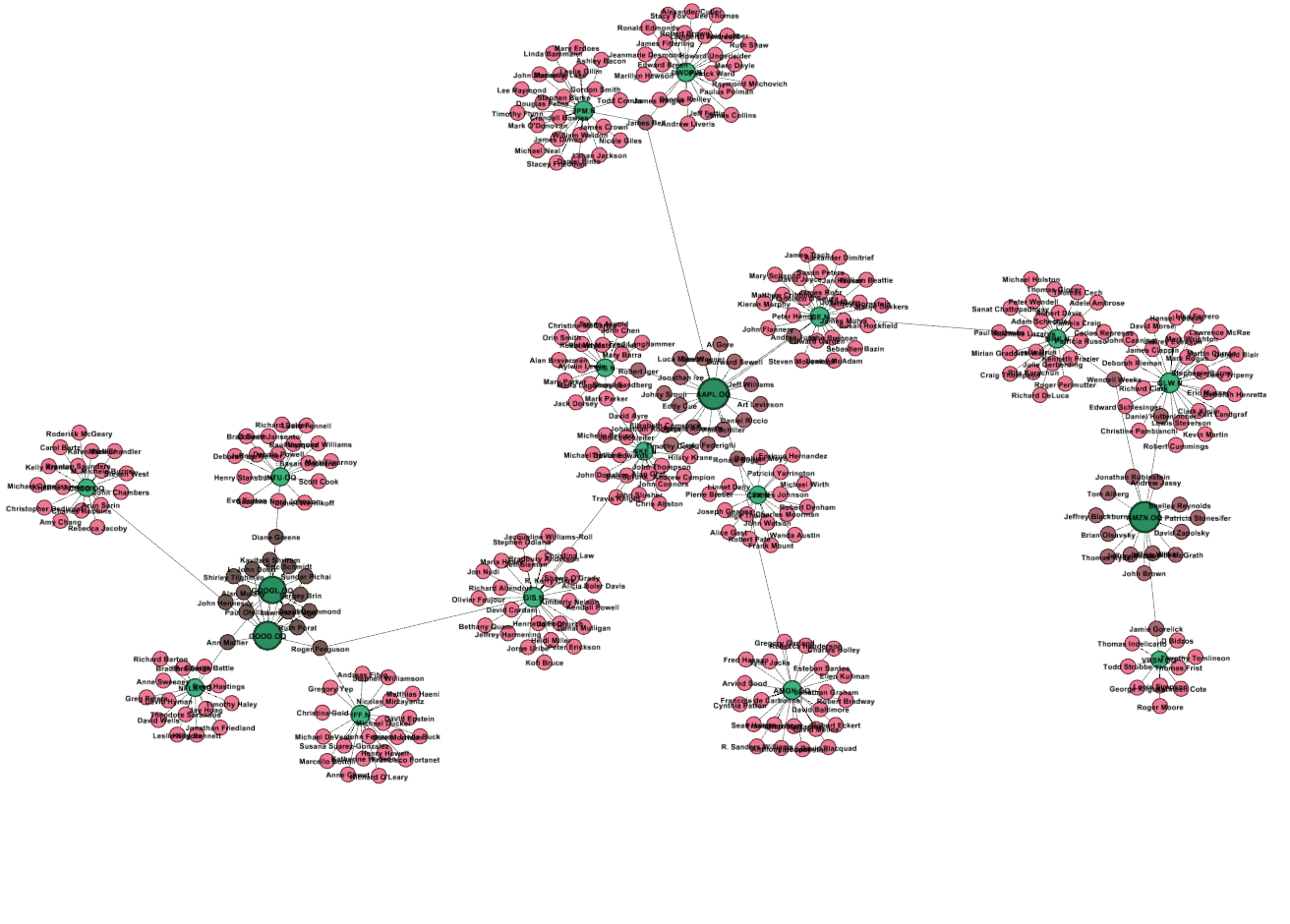
Graphs can be used in a variety of ways in predictive setups as well. We refer for more reading on this topic to:
- Node2Vec is a powerful featurization technique converting nodes in a graph to feature vectors: https://snap.stanford.edu/node2vec/
- Personalized pagerank is very often used as a featurization approach in the context of e.g. churn and fraud analytics: https://www.r-bloggers.com/from-random-walks-to-personalized-pagerank/
- Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2015). Guilt-by-constellation: fraud detection by suspicious clique memberships. Proceedings of 48 Annual Hawaii International Conference on System Sciences: Vol. accepted. HICSS-48. Kauai (Hawaii), 5-8 January 2015
- Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2014). Finding cliques in large fraudulent networks: theory and insights. Conference of the International Federation of Operational Research Societies (IFORS 2014). Barcelona (Spain), 13-18 July 2014.
- Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2014). Gotch’all! Advanced network analysis for detecting groups of fraud. PAW (Predictive Analytics World). London (UK), 29-30 October 2014
- Van Vlasselaer, V., Van Dromme, D., Baesens, B. (2013). Social network analysis for detecting spider constructions in social security fraud: new insights and challenges: vol. accepted. European Conference on Operational Research. Rome (Italy), 1-4 July 2013
- Van Vlasselaer, V., Meskens, J., Van Dromme, D., Baesens, B. (2013). Using social network knowledge for detecting spider constructions in social security fraud. Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Network Analysis and Mining. ASONAM. Niagara Falls (Canada), 25-28 August 2013 (pp. 813-820). 445 Hoes Lane, PO Box 1331, Piscataway, NJ 08855-1331, USA: IEEE Computer Society