
By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter as a “Free Tweet Consulting Experience” — where we answer a data science or analytics question of 140 characters maximum. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: Does it make sense to do categorization of continuous variables?
Our answer:
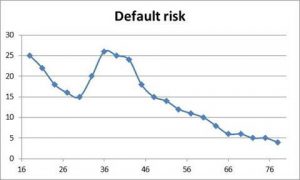
For continuous variables, categorization may be very beneficial. Consider e.g. the age variable and its risk as depicted in the figure below. Clearly, there is a non-monotonous relation between risk and age. If a non-linear model (e.g. neural network, support vector machine) would be used, then the non-linearity can be perfectly modeled. However, if a regression model would be used (which is typically more common because of its interpretability), then since it can only fit a line, it will miss out on the non-monotonicity. By categorizing the variable into ranges, part of the non-monotonicity can be taken into account in the regression. Hence, categorization of continuous variables can be useful to model non-linear effects into linear models.
 |