
By: Bart Baesens, Seppe vanden Broucke
This QA first appeared in Data Science Briefings, the DataMiningApps newsletter as a “Free Tweet Consulting Experience” — where we answer a data science or analytics question of 140 characters maximum. Also want to submit your question? Just Tweet us @DataMiningApps. Want to remain anonymous? Then send us a direct message and we’ll keep all your details private. Subscribe now for free if you want to be the first to receive our articles and stay up to data on data science news, or follow us @DataMiningApps.
You asked: Can you give me a simple explanation and example of process discovery?
Our answer:
The most common task in the area of Process Mining is called Process Discovery, where analysts aim to derive an as-is process model, starting from the data as it is recorded in process-aware information support systems, instead of starting from a to-be descriptive model and trying to align the actual data to this model. A significant advantage of Process Discovery is the fact that only a limited amount of initial data is required to perform a first – exploratory analysis.
Consider for example an insurance claim handling process. To perform a Process Discovery task, we start our analysis from a so called “event log”: a data table listing the activities that have been executed during a certain time period, together with the case (the process instance) they belong to. A simple event fragment log for the insurance claim handling process might thus look as depicted below. Activities are sorted based on the starting time. Note that multiple process instances can be active at the same moment in time. Note also that the execution of some activities can overlap.
| “Insurance claim handling” event log | |||
| Case Identifier | Start Time | Completion Time | Activity |
| Z1001 | 2013-08-13 09:43:33 | 2013-08-13 10:11:21 | Claim intake |
| Z1004 | 2013-08-13 11:55:12 | 2013-08-13 15:43:41 | Claim intake |
| Z1001 | 2013-08-13 14:31:05 | 2013-08-16 10:55:13 | Evaluate claim |
| Z1004 | 2013-08-13 16:11:14 | 2013-08-16 10:51:24 | Review Policy |
| Z1001 | 2013-08-17 11:08:51 | 2013-08-17 17:11:53 | Propose settlement |
| Z1001 | 2013-08-18 14:23:31 | 2013-08-21 09:13:41 | Calculate new premium |
| Z1004 | 2013-08-19 09:05:01 | 2013-08-21 14:42:11 | Propose settlement |
| Z1001 | 2013-08-19 12:13:25 | 2013-08-22 11:18:26 | Approve damage payment |
| Z1004 | 2013-08-21 11:15:43 | 2013-08-25 13:30:08 | Approve damage payment |
| Z1001 | 2013-08-24 10:06:08 | 2013-08-24 12:12:18 | Close claim |
| Z1004 | 2013-08-24 12:15:12 | 2013-08-25 10:36:42 | Calculate new premium |
| Z1011 | 2013-08-25 17:12:02 | 2013-08-26 14:43:32 | Claim intake |
| Z1004 | 2013-08-28 12:43:41 | 2013-08-28 13:13:11 | Close claim |
| Z1011 | 2013-08-26 15:11:05 | 2013-08-26 15:26:55 | Reject claim |
Based on real-life data as it was stored in log repositories, it is possible to derive an as-is process model, providing an overview on how the process was actually executed in real life. To do so, activities are sorted based on their starting time. Next, an algorithm iterates over all process cases, and creates “flows of work” between the activities. Activities which follow each other distinctly (no overlapping start and end time) will be put in a sequence. When the same activity is followed by different activities over various process instances, a split is created. When two or more activities’ execution overlaps in time, they are executed in parallel and are thus both flowing from a common predecessor.
After executing the Process Discovery algorithm, a process map such as the one depicted in the below figure can be obtained (using the “Disco” software package).
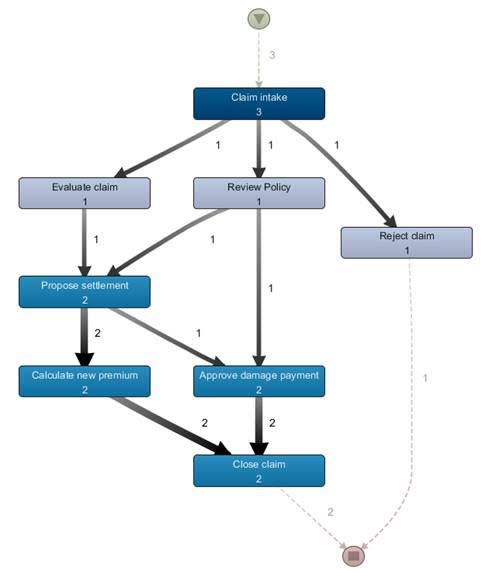 |
The process map can be further annotated by various information, such as frequency counts of an activity’s execution. The following figure shows the same process map now annotated with performance based information (mean execution time).
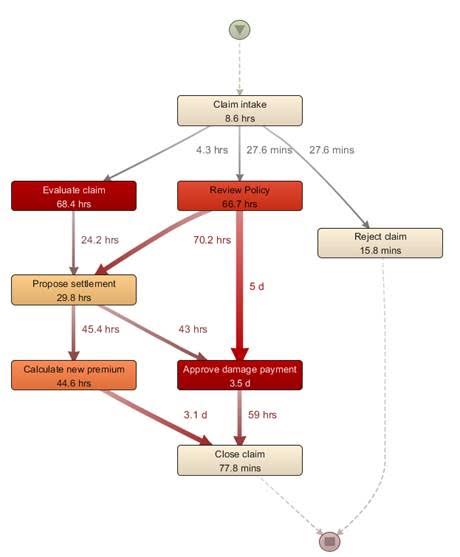 |
Note that – together with solid filtering capabilities – visualizations such as these provide an excellent means to perform an exploratory analytics task to determine bottlenecks and process deviations, compared when having to work with “flat data”-based tools (e.g. analyzing the original event log table using spreadsheet software).
As can be seen from the figures, Process Discovery provides an excellent means to perform an initial exploratory analysis of the data at hand, showing actual and true information. This allows practitioners to quickly determine bottlenecks, deviations and exceptions in the day-to-day workflows.